

Aggregator latency is one of the fastest ways to burn money in iGaming without noticing. It shows up as “slow lobby,” “game won’t load,” “stuck on launching,” and it quietly drags down session starts, wagering volume, and retention. The uncomfortable part is that it is rarely one big issue. It is dozens of small network and application delays stacked together, multiplied by geography.
This guide focuses on two levers that consistently move the needle:
- Caching (what you can safely cache, where to cache it, and how not to break compliance or game integrity)
- Regional peering (how to cut unnecessary network distance between your casino, your aggregator, and the game providers)
What “aggregator latency” actually includes
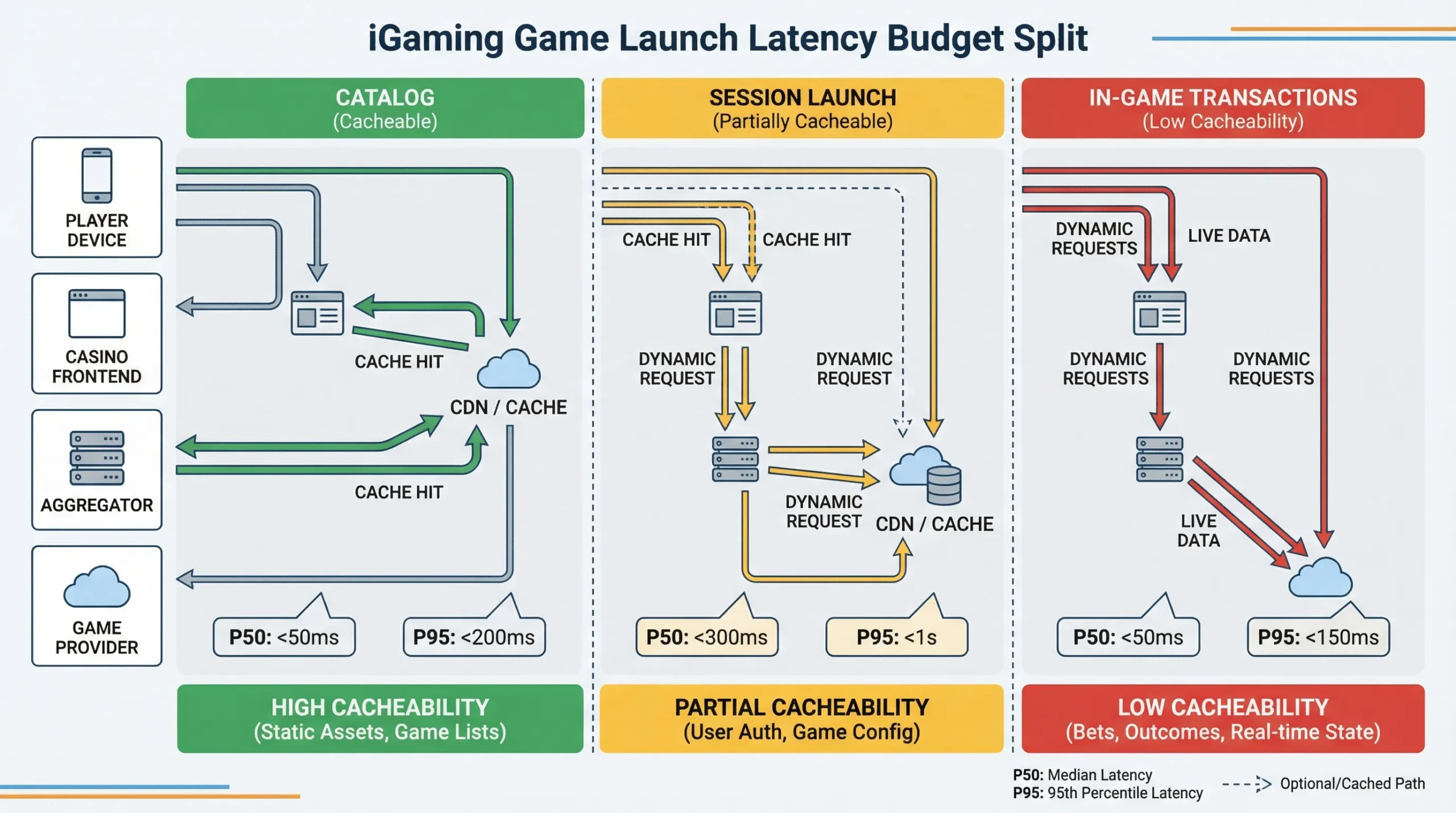
Most teams measure “game launch time” as a single number, but you can only reduce it if you split it into stages.
A typical iGaming aggregator path has three distinct latency zones:
1) Lobby and catalog latency
This is everything required to show a game list, thumbnails, providers, RTP labels, jurisdictions, and “play” buttons.
Common calls:
- Game catalog fetch (filters, pagination)
- Per-game metadata fetch (tags, volatility, jurisdictions)
- Asset delivery (images, preview videos, scripts)
This zone is highly cacheable, and it is where you can often get the biggest “feel faster” improvement.
2) Game launch and session initialization latency
This is the critical path between tapping “Play” and seeing a playable game.
Common calls:
- Create launch session (operator to aggregator)
- Create provider session (aggregator to studio)
- Token exchange / signature verification
- Return launch URL (or iframe payload)
This zone is partially cacheable (mostly configuration and routing decisions). The session creation itself is not.
3) In-game transactional latency
This is the steady-state loop once the game is running.
Common calls:
- Balance reads
- Bet placement
- Win settlement
- Bonus hooks and promotional eligibility checks
This zone is mostly not cacheable (you are moving money), but it is very sensitive to network round trips and connection setup overhead.
Step zero: instrument latency like a production system, not a dashboard
Before changing caching or network topology, make sure you can answer these four questions with traces and real-user data:
- What is P50, P95, and P99 launch time by country (not just global average)?
- Which hop is slow, operator edge to aggregator, aggregator to provider, or provider back to player?
- Is the latency compute-bound (slow service) or RTT-bound (slow path)?
- How much time is spent on DNS + TCP + TLS versus application processing?
Practical notes that matter in iGaming:
- Use distributed tracing with trace propagation across services (W3C
traceparentworks well across polyglot stacks). - Add region labels at every hop (player approximate region, POP, cloud region, provider region).
- Correlate with error modes. Latency and failure usually travel together (timeouts, retries, token refreshes).
If you only have one KPI, make it: P95 time-to-first-spin (or equivalent “first interactive moment”) by region.
Caching: where to cache in a casino aggregation stack
Caching is not a single technique. It is a set of placement decisions:
- Browser or app cache
- CDN edge cache
- API gateway cache
- Service-level cache (Redis, in-memory)
- Database read replicas and materialized views (not “cache” in the strict sense, but the same intent)
The key is to cache the right objects with explicit invalidation rules.
What you can cache safely (and what you should not)
Here is a practical cheat sheet for iGaming aggregation.
| Object / API response | Cacheability | Where it should live | Typical TTL strategy | Notes for iGaming compliance |
|---|---|---|---|---|
| Game catalog (list views) | High | CDN edge + gateway | Minutes to hours | Must respect jurisdiction and brand visibility rules |
| Game metadata (RTP label, tags, volatility label, provider info) | High | CDN edge + service cache | Hours with background refresh | Keep a version field to invalidate quickly |
| Game assets (thumbs, banners, static scripts) | Very high | CDN edge | Days to weeks | Use immutable URLs via content hashes |
| Provider capability matrix (jurisdiction support, currencies) | Medium to high | Service cache | Minutes to hours | Changes can be operationally urgent, keep fast purge |
| Launch config templates (per provider) | Medium | Service cache | Minutes | Safe if templated, do not cache player tokens |
| Player balance | Low | Usually none (or micro-cache) | 0 to a few seconds | Micro-caching can help UI, but do not create stale money |
| Bet settlement responses | None | None | N/A | Ledger correctness beats speed |
1) Cache the catalog at the edge, but make it jurisdiction-aware
Most casinos accidentally disable caching by making catalog responses “personalized” when they do not need to be.
Two patterns to avoid:
- Returning the entire catalog based on player ID when you only need geo, brand, and eligibility tier
- Mixing “static” game data with “dynamic” data (like live jackpots) in one response
A cleaner pattern:
- Static catalog endpoint that varies only by safe dimensions (brand, locale, jurisdiction)
- Separate dynamic overlays (jackpots, “trending now,” availability) served from low-latency services
This lets you cache 80 to 95 percent of the payload while keeping the dynamic parts fresh.
2) Use stale-while-revalidate for “always-on” lobby speed
In iGaming, a slightly stale thumbnail is almost never a compliance issue, but a slow lobby is always a revenue issue.
A strong pattern is:
- Serve cached content immediately
- Refresh in the background
- Only block if the content is beyond a strict max staleness window
If you operate in markets where content availability changes quickly (for example, due to regulatory updates), pair this with an emergency purge channel (tag-based purge or version-based invalidation).
3) Precompute “allowed games” sets per jurisdiction and brand
Many aggregators burn CPU and latency recomputing eligibility per request.
Instead:
- Precompute allowed-provider and allowed-game sets per jurisdiction (and per brand if necessary)
- Store them in a fast cache keyed by
(brand, jurisdiction, device class) - Only recompute on policy changes
This is especially effective if you enforce compliance whitelists or content blocking rules, because it turns repeated per-request logic into a cache lookup.
4) Cache provider routing decisions, not sessions
You cannot cache a session token, but you can cache everything that decides where a session should go.
Examples of cacheable routing inputs:
- Provider endpoint selection per region
- Fallback order when a provider POP is degraded
- Currency and country support
When a player hits “Play,” you want the remaining work to be:
- Create operator session
- Call provider session create
- Return URL
Not: compute eligibility, look up capabilities, test endpoints, discover provider region, then create session.
5) Do not forget connection-level “caching” (TLS and TCP)
A surprisingly large chunk of “aggregator latency” is handshake overhead.
High-impact tactics:
- Keep provider connections warm with pooling (HTTP/2 where supported)
- Enable TLS session resumption
- Reduce DNS churn (sane TTLs, avoid unnecessary per-request lookups)
None of these changes your business logic, but they reduce tail latency, especially at P95 and P99.
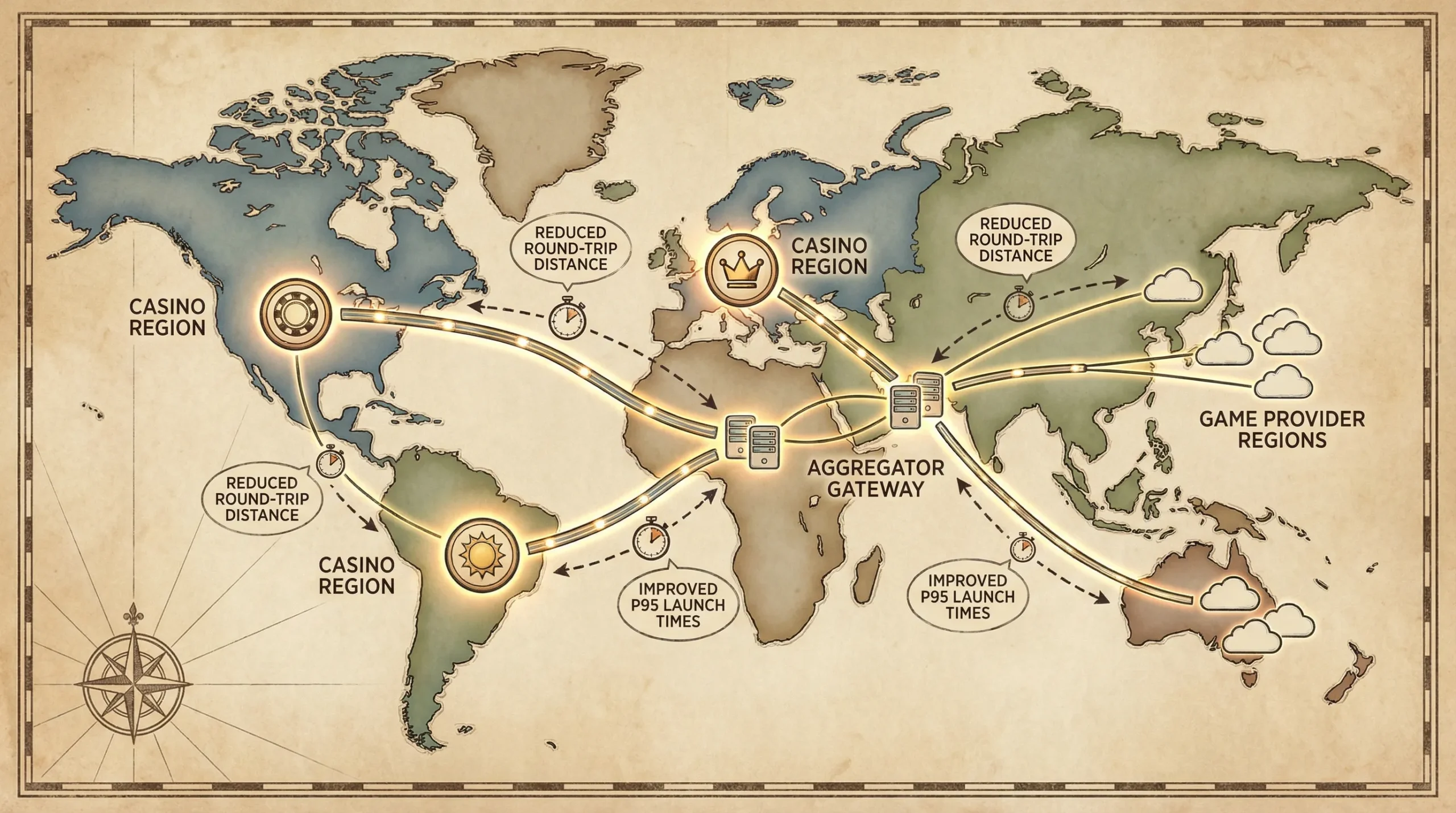
Regional peering: cut physical distance, not just milliseconds
Caching improves the lobby and reduces repeated work. Peering improves the critical path that cannot be cached.
The mental model: every unnecessary network hop creates tail latency, and iGaming lives in the tail.
When regional peering beats “just add a CDN”
A CDN helps with static assets and cacheable API responses. It does not fix:
- Aggregator to provider session creation RTT
- Wallet and settlement calls
- Studio-side POP distance problems
If your traces show the slow hop is aggregator to provider (or provider back to you), you need to reduce the network path.
Three peering models that work in practice
1) Multi-region aggregator gateways close to players
Run your aggregation gateway in the same regions as your largest cohorts, for example North America, Western Europe, LATAM.
Key requirement: stateless gateways with shared configuration and a secure control plane. You do not want to replicate complex state.
What changes:
- Player to aggregator RTT drops significantly
- Provider session calls originate from the closest region (sometimes)
What does not automatically improve:
- If the provider endpoint is still far away, you still pay that distance
2) Co-locate or peer close to major providers
Some latency is driven by where studios host their session endpoints and game servers. If your aggregator is in Region A and the studio is in Region B, you always pay that RTT.
Options:
- Deploy a regional connector near the provider region
- Use private connectivity options where available (cloud interconnects, dedicated peering)
The goal is to avoid long, variable public-internet paths for the non-cacheable calls.
3) Use an IXP-heavy edge strategy (when you scale globally)
If you operate at significant scale, Internet Exchange Point proximity can materially improve stability and tail latency, because you reduce transit dependencies.
This is not required for every operator, but it matters when:
- You have meaningful traffic in many countries
- You see frequent route changes or jitter spikes
- Your business is sensitive to “random bad nights” in a region
A simple decision matrix: where to place what
| Component | Best default placement | Why |
|---|---|---|
| Lobby assets and catalog | CDN edge | Lowest cost per ms saved |
| Launch gateway | Multi-region near players | Protects time-to-first-spin |
| Provider connectors | Near studios or in shared low-latency hubs | Reduces non-cacheable RTT |
| Ledger and compliance services | Region aligned with regulatory and data residency needs | Correctness, auditability, locality |
Pitfalls: the ways caching and peering can backfire in iGaming
Cache poisoning and “wrong jurisdiction” leaks
If you cache catalog responses without correctly varying on jurisdiction and brand, you can serve restricted content to the wrong cohort. That is a compliance and reputational risk.
Mitigation:
- Use explicit cache keys (brand, jurisdiction, locale)
- Do not include user identifiers unless required
- Add automated tests that request the same endpoint across two jurisdictions and diff the results
Stale capability data breaks launches
Provider capability matrices change, sometimes quickly (maintenance windows, jurisdiction rollouts, currency support). If your cache TTL is too long, players click “Play” and fail.
Mitigation:
- Short TTLs for capability data
- Background refresh
- Fast purge triggered by provider health events
Peering without observability creates blind spots
When you add regions or connectors, you increase system complexity. If you cannot see per-region error rates and P95, you will ship problems faster.
Mitigation:
- Per-region SLOs for launch success rate and P95 launch latency
- Health-based routing with strict guardrails (fail closed where compliance demands)
A practical 14-day plan to reduce aggregator latency
Days 1 to 3: measure and segment
- Implement end-to-end tracing on launch flows (operator, aggregator, provider)
- Publish P50/P95/P99 by country and device class
- Identify top three slow corridors (for example, Brazil to EU region, Philippines to US region)
Days 4 to 7: ship “safe caching” improvements
- Edge-cache catalog and metadata responses with jurisdiction-safe keys
- Make assets immutable and cacheable (content-hash URLs)
- Add stale-while-revalidate and purge hooks
Days 8 to 14: reduce RTT for non-cacheable calls
- Stand up a regional launch gateway in the worst-performing region
- Route provider session creation via the closest connector
- Validate improvements with A/B splits and tail-latency tracking
Where Spinlab fits (if you are evaluating platform choices)
If you are building or upgrading a casino on a modular iGaming platform, aggregator latency is not just “a games problem.” It touches your cashier, compliance rules, and real-time analytics.
Spinlab’s platform is designed around modular components like game aggregation, payments (crypto and fiat), KYC and AML compliance, fraud prevention, and real-time analytics, which can make it easier to centralize instrumentation and enforce jurisdiction rules while you optimize performance. For teams that want a Shopify-like operating experience (without a long custom build), the main advantage is usually speed of iteration and faster onboarding.
If you are also distributing original casino games across multiple brands and regions, performance is only one side of scaling. Protecting your IP and licensing rights becomes a parallel track. Tools like Third Chair’s IP monitoring and licensing workflows are a useful reference point for how AI-driven enforcement can support growth when content becomes a core asset.
Frequently Asked Questions
What is the biggest cause of aggregator latency in online casinos? It is usually network round trips across regions, combined with non-cacheable session creation calls. Lobby payload size and uncached metadata are common secondary drivers.
Is caching safe for iGaming catalog and game metadata? Yes, if you vary cache keys by brand, jurisdiction, and locale, and you keep a fast invalidation mechanism for policy and provider changes.
Does a CDN solve game launch latency? A CDN helps for static assets and cacheable APIs, but it does not remove RTT for session creation, wallet calls, and settlement. For that, you need better regional placement and peering.
How do I know if I need regional peering or just better caching? If traces show most time is spent on catalog and metadata, caching is the lever. If most time is aggregator to provider (or provider back), you need to reduce distance with regional gateways, connectors, or peering.
What metric should I optimize for first? P95 time-to-first-spin (or first interactive moment) by country, because it captures the real player experience and is sensitive to tail latency.
Want help cutting launch time without breaking compliance?
If you are planning a new casino build or you are migrating from a fragmented stack, Spinlab Studio can help you design an architecture that reduces aggregator latency with jurisdiction-safe caching, regional rollout planning, and end-to-end instrumentation.
Explore the platform at spinlab.studio and book a walkthrough to map your current latency budget and fastest wins.