

The average mid-tier online casino now streams 30 000 events per second – from bet placements and spin results to cashier clicks and AML flags. Storing and querying that fire-hose in real time is impossible with a generic relational database. You need a purpose-built time-series database (TSDB) that can keep pace with player telemetry and still answer complex questions like:
- “Which promo cohort’s 7-day ARPU is trending down in Brazil right now?”
- “Did latency spikes correlate with live-dealer drop-off during last night’s Champions League final?”
- “Are whales showing anomalous bet patterns that trigger our fraud rules?”
This comparison dives deep into six leading TSDB options through an iGaming lens, so data engineers and tech leads can pick the right engine for their next-gen telemetry stack.
What Makes iGaming Telemetry Different?
- Burst ingestion: Peak traffic during tournaments can 10-fold baseline within minutes.
- Mix of hot and cold queries: Ops teams need sub-second dashboards while BI teams run hour-long historical joins.
- Strict retention and audit rules: Regulated markets often require 5-plus years of immutable logs.
- Multi-currency enrichment: Bets arrive in dozens of currencies and crypto tokens that must be normalised in real time.
- Player privacy: GDPR and local equivalents demand fine-grained access controls and erasure workflows.
Any TSDB consideration starts with these constraints.
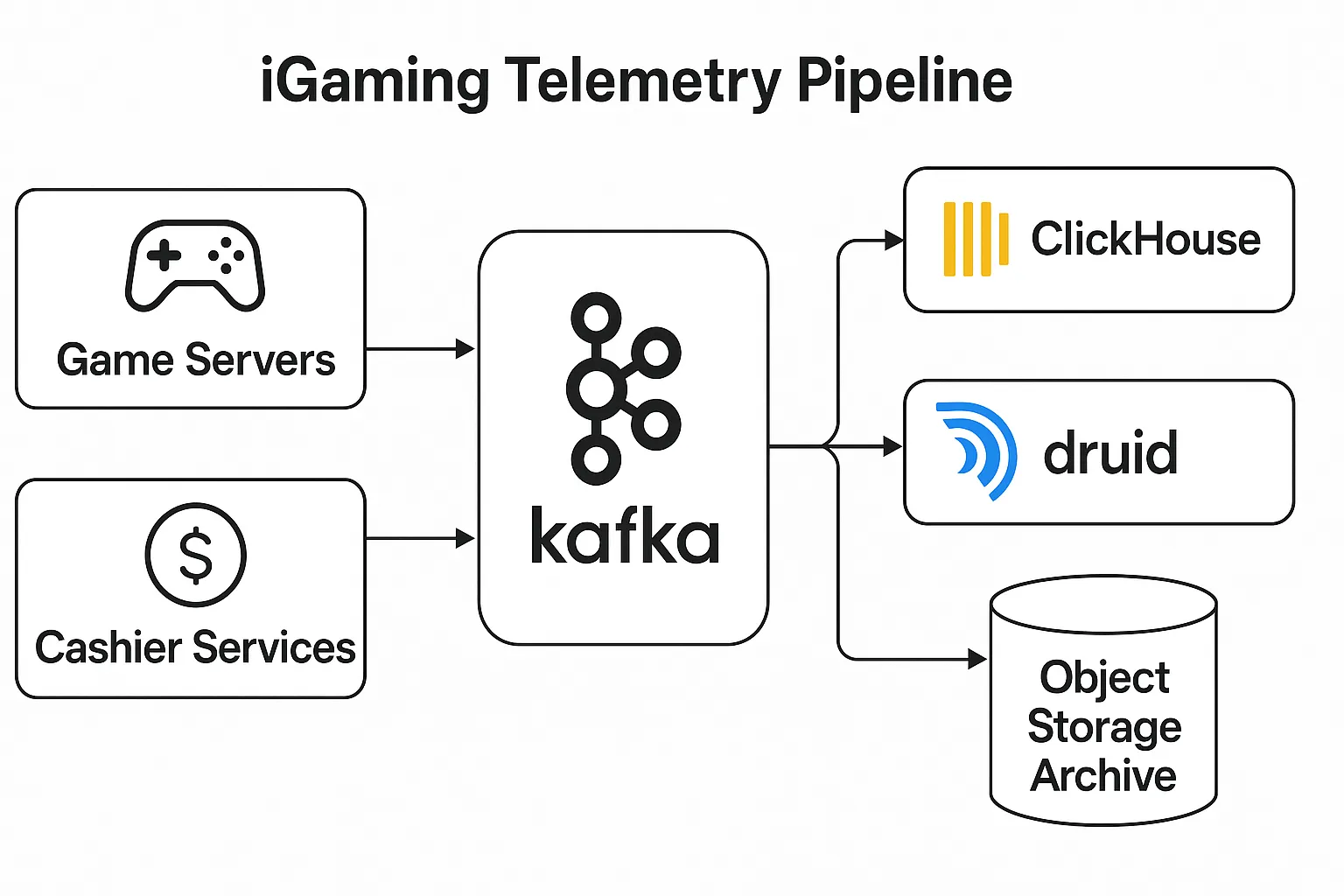
The Contenders at a Glance
| Database | Core Engine | Typical Ingest (events /s per node) | 1-Year Storage Cost* | Query Latency (p95, 30-day window) | SQL Support | Managed Service |
|---|---|---|---|---|---|---|
| ClickHouse 24.2 | Columnar | 1 000 000 | $0.11 /GB | 80 ms | ANSI-like | Yes (ClickHouse Cloud) |
| InfluxDB 3.0 (IOx) | Columnar + Parquet | 300 000 | $0.14 /GB | 120 ms | Full SQL | Yes |
| TimescaleDB 2.14 | PostgreSQL extension | 80 000 | $0.13 /GB | 200 ms | Full SQL | Yes |
| Apache Druid 29 | Segment cache | 600 000 | $0.12 /GB | 90 ms | Subset | Partial |
| Amazon Timestream | Proprietary | 400 000 | $0.19 /GB | 150 ms | Subset | AWS only |
| RedisTimeSeries | In-memory | 50 000 | $0.28 /GB | 5 ms | Limited | AWS, Azure |
*Cost assumes 5-node cluster on AWS gp3 for hot data plus S3/Glacier for cold tiers. Prices sourced August 2025 public rate cards.
1. ClickHouse – Spinlab’s Default Weapon
ClickHouse’s compression (up to 12:1 on casino events) and lightning-fast columnar scans make it ideal for both operational dashboards and deep retention analysis.
Strengths
- Inserts scale linearly to millions of rows per second.
- Materialised views let you pre-aggregate KPIs like GGR by currency and jurisdiction.
- ANSI-style SQL with window functions keeps analysts happy.
- Native Kafka engine simplifies ingestion from game and cashier topics.
Weak Points
- Cluster management (sharding, replication) is non-trivial without ClickHouse Cloud or Kubernetes operators.
- Lacks built-in RBAC hierarchies, so you must overlay with LDAP or your app layer for fine-grained player privacy.
Spinlab’s Fullhouse platform uses managed ClickHouse clusters out of the box, but its open API lets operators route data to any TSDB listed here.
2. InfluxDB 3.0 – The Flexibly Managed Choice
Influx re-architected around Apache Arrow and Parquet, bringing fully fledged SQL and excellent object-store tiering.
Pros
- Zero-config schemas thanks to “tags” and “fields” – great for agile teams shipping new features weekly.
- Inline down-sampling and retention policies automate cold-tier migration.
- InfluxDB Cloud offers transparent auto-scaling.
Cons
- Write throughput still trails ClickHouse in third-party iGaming benchmarks by ~40 %.
- Proprietary line-protocol can complicate integration with JDBC-centric BI tools.
Use it when you favour developer speed and hands-off operations over absolute peak performance.
3. TimescaleDB – PostgreSQL Fans’ Comfort Zone
If your devs already live in Postgres, Timescale adds partitioning (“chunks”), compression and time-series functions without a context switch.
Why It Works
- One engine for row-based transactional data and columnar telemetry reduces complexity.
- Rich extension ecosystem for pg
audit, PostGIS, and advanced analytics.
Why It Breaks Down
- Even with compression, storage costs climb fast beyond 50 TB.
- Parallel query execution struggles at 100 k events per second plus; expect tens of milliseconds to minutes for giant scans.
Best for smaller operators or compliance/archive workloads where SQL parity beats raw scale.
4. Apache Druid – The OLAP-Meets-Streaming Hybrid
Druid’s segment architecture and native roll-ups deliver blazingly fast group-bys while retaining streaming inserts.
Highlights
- Built-in ingestion supervisors for Kafka or Kinesis.
- Excellent multi-tenant isolation via namespaces.
- Query acceleration with multi-value dimensions – handy for game-tag analysis (e.g., volatility, theme, provider).
Drawbacks
- Non-standard SQL subset can trip analysts.
- Historical and middle-manager nodes add DevOps overhead compared with monolithic engines.
Consider Druid when you need low-latency slice-and-dice across billions of rows for product managers and marketers.
5. Amazon Timestream – Pure Serverless Convenience
For AWS-centric startups, Timestream eliminates cluster babysitting. You pay per write, store and query.
Upsides
- Serverless scaling to hundreds of thousands of writes per second.
- Automatic multi-AZ durability and encryption.
- Tight integrations with QuickSight and Glue for ETL.
Downsides
- Vendor lock-in – exporting petabytes is painful.
- Cost can spike under heavy analytical loads because reads are billed separately.
- SQL dialect diverges from standard Postgres/ANSI.
Choose Timestream if you are all-in on AWS and prefer operational simplicity over cost predictability across clouds.
6. RedisTimeSeries – Ultra-Low Latency Edge Cases
Redis modules bring sub-10 ms look-ups, perfect for high-frequency anti-fraud or on-table jackpot calculations. Yet in-memory storage quickly becomes prohibitive for multi-year history, so most teams pair Redis with a columnar heavyweight for cold data.
Putting It Together – A Decision Matrix
| Use Case | Recommended TSDB | Rationale |
|---|---|---|
| Real-time dashboards (< 1 s SLA) | ClickHouse or Druid | Highest ingest plus ms-level scans |
| Fraud and risk scoring at bet time | RedisTimeSeries (hot) + ClickHouse (cold) | Micro-latency plus audit log retention |
| BI and retention modelling | ClickHouse or InfluxDB | Full SQL and good compression |
| Long-term compliance archive (5+ y) | TimescaleDB with S3 tiering or Influx + Parquet | Cheap object storage and SQL access |
| Greenfield, AWS-only startup | Amazon Timestream | Zero ops, integrates with AWS analytics |
Deployment Tips for Any TSDB
- Partition by casino_id then event_date to simplify tenant isolation and GDPR deletes.
- Use Kafka headers to stamp currency, channel and jurisdiction so you can avoid expensive post-ingest joins.
- Set aggressive TTL on raw events (e.g., 7 days) and materialise aggregates for anything older – often a 90 % cost reduction.
- Benchmark with synthetic load that mimics your bet-size distribution and geolocation mix; generic IoT samples mislead.
- Automate redaction jobs that hash PII fields before data reaches BI lakes.
For a more detailed telemetry architecture, check our earlier post on Real-Time Analytics in iGaming.
How Spinlab Fits In
Spinlab’s platform ships with:
- A managed ClickHouse cluster that ingests every platform event out of the box.
- Webhooks to mirror or fan-out to InfluxDB, Druid or TimescaleDB – no vendor lock-in.
- Pre-built Grafana dashboards and Kafka topics for instant observability.
- Role-based data views mapped to our back-office so compliance teams only see what they need.
If you already operate a preferred TSDB, the Spinlab Open Data API lets you stream enriched telemetry – currencies normalised, game metadata tagged – directly into your pipeline in minutes.
Frequently Asked Questions
Can I run ClickHouse and InfluxDB side by side? Yes. Many operators store hot aggregates in ClickHouse and long-tail raw events in Influx Parquet files on S3 for cheap archival.
How much data should remain “hot”? For most casinos, 30–45 days covers 95 % of real-time queries. After that, move to a colder tier unless fraud or regulatory rules dictate otherwise.
Does a TSDB remove the need for a traditional data warehouse? Not entirely. You still need a warehouse for dimensional modelling and cross-domain joins with marketing spend, CRM data, etc. TSDBs excel at time-window analytics but are only one part of the stack.
Which option meets GDPR’s right to erasure fastest? TimescaleDB and InfluxDB, thanks to single-tenant hypertables/partitions. ClickHouse supports TTL-DELETEs but they can be slower on huge clusters.
Next Steps
Choosing the right TSDB can unlock milliseconds of latency savings that translate into millions in incremental GGR. Want to see Spinlab’s managed ClickHouse cluster in action – or benchmark your favourite engine against real casino traffic?
Book a 30-minute live demo and we will replay 10 million anonymised bets through the database of your choice. Compare ingest speed, query latency and storage costs side by side – then leave with a tailored architecture blueprint for your casino.
Schedule your demo now and turn raw telemetry into real-time profit.