

Downtime in iGaming is different from downtime in most SaaS. A 90-second wallet lag can trigger abandoned deposits, a misrouted webhook can double-credit, and a “small” game-launch latency spike can cascade into support tickets, affiliate disputes, and regulator questions.
That’s why observability for iGaming cannot be an afterthought. You need a system that answers, in minutes, not hours:
- What is broken?
- Who is affected (which markets, payment rails, game providers, cohorts)?
- Where in the flow did it fail?
- What should we do right now to stop player harm and revenue leakage?
This guide gives you a practical, operator-focused blueprint: the metrics, traces, and alerts to use, plus how to stitch them together into incident-ready dashboards.
What makes observability in iGaming uniquely hard
iGaming platforms combine characteristics that make classic “web app monitoring” insufficient:
Real money flows and irreversible side effects
A deposit, bonus award, bet, or withdrawal is not just a request. It is a financial and compliance event with side effects across ledgers, PSPs, fraud engines, and player communications. Observability must prove correctness (and replayability) under retries, webhook redelivery, and partial failures.
If you are building payments and wallet primitives, idempotency and state transitions must be observable, not assumed (Spinlab has a deeper technical piece on idempotency for casino payments).
Third-party dependency chains
Your availability is often a product of upstream providers:
- Payment gateways and bank rails
- KYC and AML vendors
- Game providers and aggregators
- SMS/email delivery
- On-chain RPC providers (for crypto)
If you only monitor your own services, you will page too late and diagnose too slowly.
Adversarial pressure
Bots, card-testing, bonus abuse, and account takeover create “traffic” that looks like growth until it flips into losses and operational overload. You need security, fraud, and product telemetry in the same observability loop.
Multi-jurisdiction constraints
You also need audit-grade evidence: what happened, when, to whom, under which policy version, with retention controls that respect privacy and local rules.
The observability model: metrics + traces + logs + decision context
Most teams talk about the three pillars:
- Metrics: fast, aggregated health signals
- Traces: end-to-end request and workflow visibility
- Logs: detailed, queryable forensic context
In iGaming, there’s a fourth pillar that matters in practice: decision context.
That includes:
- Risk decisions (fraud score, step-up auth, withdrawal holds)
- Compliance decisions (KYC status, AML rule hits, jurisdiction policies)
- Money movement decisions (ledger posting outcomes, reconciliation states)
If those decisions are not observable (with reason codes and versioning), you cannot explain incidents to finance, support, or regulators.
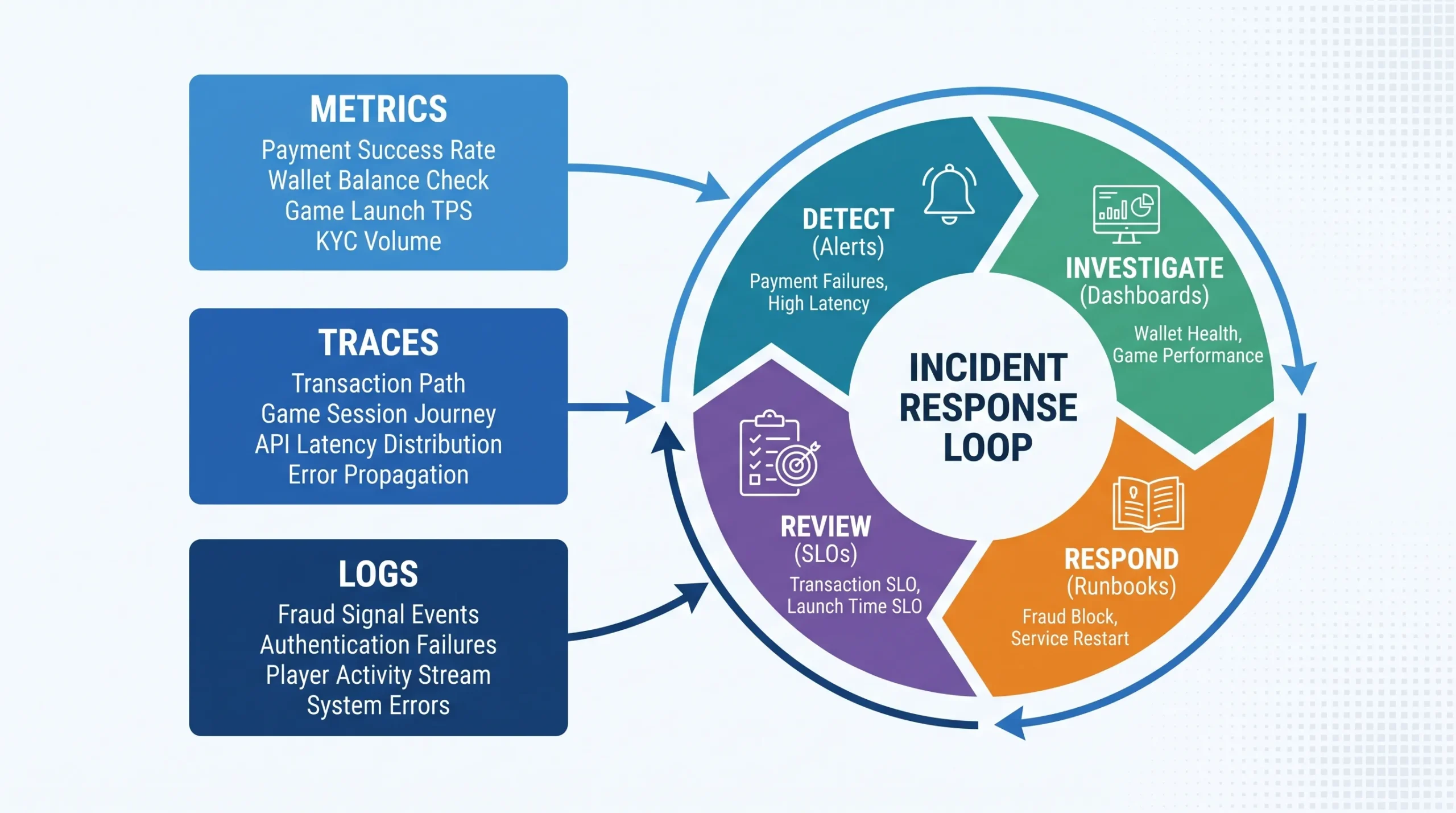
Step 1: Define your “critical player journeys” and assign SLOs
Before choosing alerts, decide what “reliability” means in player terms. In iGaming, SLOs should map to journeys, not microservices.
A practical starting set:
- Register to verified (or to “allowed to deposit”) success rate and time
- Deposit initiated to balance credited success rate and time
- Game launch success rate and time to first spin
- Bet placement to settlement success rate and time
- Withdrawal requested to paid success rate and time (including manual review)
Use the Google SRE concepts of SLIs/SLOs and error budgets as your foundation (Site Reliability Engineering book).
SLO design tips that work well for casinos
- Use percentiles (P50/P95/P99) for latency, not averages.
- Segment SLOs by rail, provider, and market (a global aggregate hides localized fires).
- Define “success” precisely (for example, deposit success is not “PSP authorized,” it is “funds are playable in the casino wallet”).
Step 2: Instrument with correlation IDs that match iGaming reality
Traces and logs are only useful if you can follow an event across systems. Standardize a set of IDs and propagate them everywhere.
Recommended correlation fields:
player_id(internal, non-PII surrogate key)jurisdiction/brand_idsession_id(casino session)device_id(or fingerprint ID, if applicable)payment_intent_id(rail-agnostic)psp_transaction_id(rail-specific)wallet_transaction_id(ledger)game_session_idandgame_round_idprovider_request_id(game provider or aggregator)bonus_instance_id(if promotions are involved)kyc_case_id/aml_case_id(when relevant)
If you use OpenTelemetry, propagate these as span attributes (and also inject them into structured logs). OpenTelemetry’s spec and SDKs are the most portable way to avoid vendor lock-in (OpenTelemetry).
Step 3: The metrics to track (by domain)
Below is a practical metric set that most iGaming teams can adopt without boiling the ocean.
Platform “golden signals” (baseline)
At minimum, every platform should expose:
- Request rate (RPS)
- Errors (by type and user impact)
- Latency percentiles
- Saturation (CPU, memory, queue depth, DB connections)
These are table stakes. The iGaming-specific value comes from domain metrics that predict churn and loss.
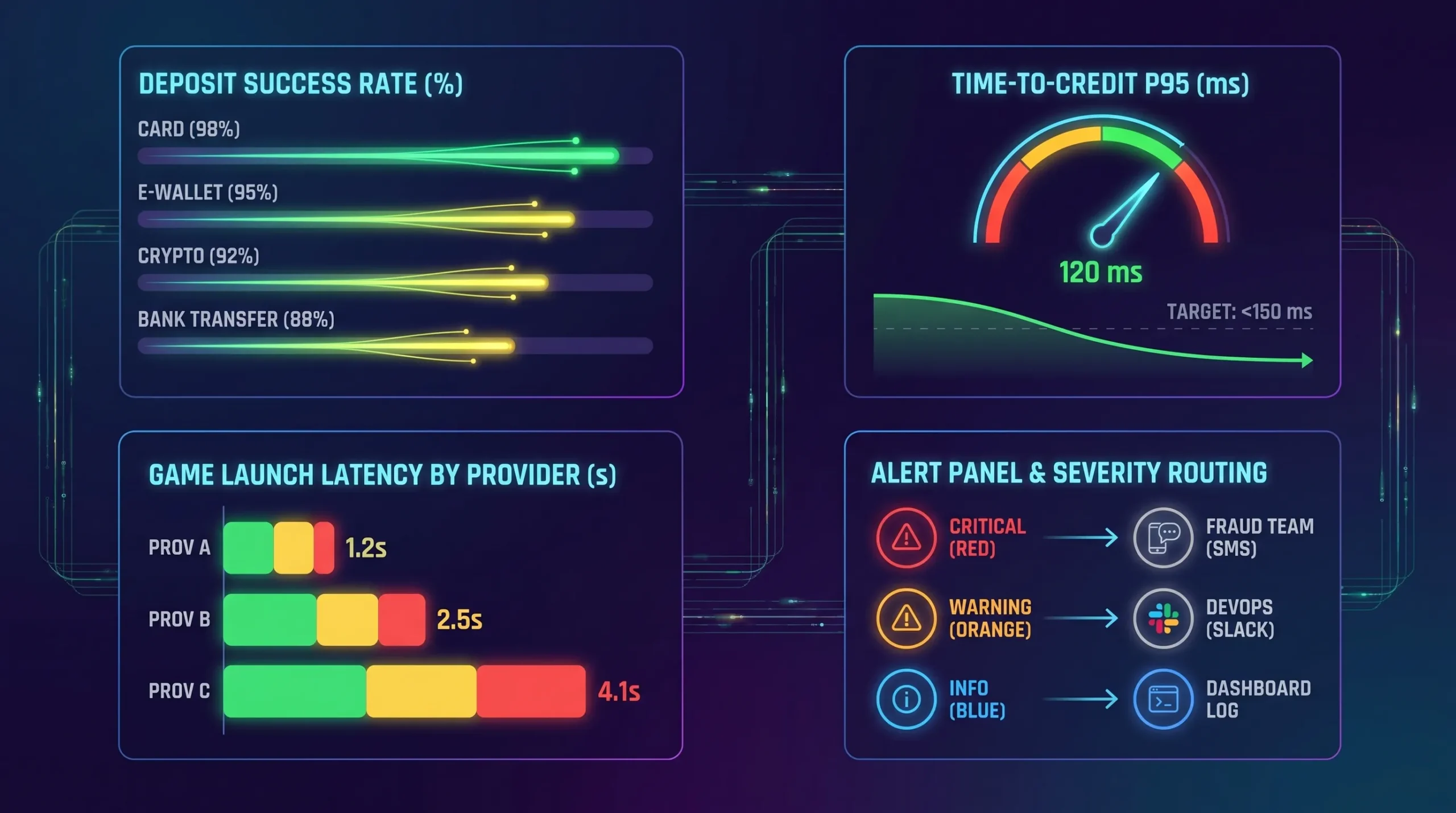
Cashier and payments metrics
Cashier issues are often the fastest path to lost revenue. Track these by rail, provider, issuer/BIN (where allowed), and country.
| Metric | Why it matters | Alert suggestion (starting point) |
|---|---|---|
| Deposit initiation rate | Detect broken CTA, UI errors, geo blocks | Sudden drop vs 7-day baseline per market |
| Authorization/approval rate | Core conversion metric | Drop > X% for 10-15 min on a rail/provider |
| Time-to-credit (P95) | Players feel “stuck” even if PSP succeeded | P95 exceeds SLO for 2 windows |
| Soft vs hard decline ratio | Diagnoses routing and issuer behavior | Spike in soft declines often means retry/routing opportunity |
| Webhook delivery lag | Webhook queues are silent killers | P95 lag > N minutes, plus backlog growth |
| Duplicate credit prevented count | Early warning for idempotency stress | Any sustained spike warrants investigation |
If you want a deeper taxonomy of payment failures and how to bucket them, Spinlab’s guide on payment failures in iGaming is a useful reference.
Wallet and ledger correctness metrics
Wallet incidents are existential. You need metrics that prove your ledger is consistent and that money movement is deterministic.
Track:
- Ledger posting success rate
- Posting latency (P95/P99)
- Negative balance count (and total exposure)
- Reversal/chargeback rates by rail
- Reconciliation mismatch rate (ledger vs PSP vs bank/on-chain)
A good companion topic is payments reconciliation. If you run a three-way match, your observability should mirror it (casino payments reconciliation).
Game launch and gameplay metrics
Players rarely complain “your game aggregator endpoint is slow.” They complain “the slot won’t load.” Monitor the real experience:
- Game launch success rate (by provider, studio, region)
- Time to first frame / time to first spin (P95)
- In-session transaction error rate (bet, win, rollback)
- Provider timeout rate and retry rate
- Session drop rate (unexpected disconnects)
KYC, AML, and fraud control health
Compliance and fraud systems can silently degrade conversion if not monitored with the same rigor as payments.
Track:
- KYC start rate and completion rate
- Verification latency percentiles
- Resubmission rate (bad UX, poor doc capture)
- Manual review queue depth and age
- Fraud rule hit rate (by rule/version)
- False-positive proxy metrics (for example, “blocked deposit attempts that later pass KYC”)
Support and operational pain signals (often overlooked)
Some of your best “early warnings” live outside infrastructure metrics:
- Withdrawal ticket volume per 1,000 withdrawals
- Payment-related ticket share
- Refund/chargeback contacts
- Live chat wait time
If tickets spike, an incident is already impacting players, even if your dashboards look green.
Step 4: Distributed tracing for iGaming workflows (what to trace)
Metrics tell you that something is wrong. Traces tell you where.
Trace the journeys that create irreversible side effects
Prioritize these traces first:
- Deposit (intent created → PSP authorize → webhook → ledger posting → bonus side effects → playable balance)
- Withdrawal (request → risk decision → compliance checks → payout execution → settlement confirmation)
- Game launch (lobby click → session negotiation → wallet callbacks → provider launch URL → client load)
- Bet lifecycle (bet debit → provider ack → result → credit or rollback)
Span naming and attributes that speed up diagnosis
A trace that’s useful at 3 a.m. includes:
- Span attributes:
rail,psp,provider,studio,country,currency,jurisdiction,brand_id - Outcome attributes:
result=success|failed|pending,failure_reason_code - Idempotency attributes:
idempotency_key,dedupe_hit=true|false
Also include links between async components (webhooks, queues, event streams). If your deposit flow crosses a queue, add trace context propagation to consumers.
Sampling strategy that fits iGaming volume
Full-fidelity tracing for everything is expensive. A pragmatic approach:
- Head sample low (for example, 1% to 5%) globally
- Always sample error traces
- Tail-sample “slow” traces (latency above threshold)
- Force-sample VIP or high-value cohorts (careful with privacy and policy)
Step 5: Alerting that reduces noise and catches revenue-impact fast
Most iGaming teams suffer from one of two failures:
- Too few alerts, incidents are detected by players
- Too many alerts, on-call is numb, real issues are missed
A practical alert hierarchy
Use three tiers:
1) Page on symptom alerts (player impact)
Examples:
- Deposit success rate below SLO (per rail/provider)
- Game launch failures above threshold (per provider)
- Withdrawal time-to-paid P95 above SLO
These should be relatively few and tied to SLOs.
2) Ticket on cause and capacity alerts (actionable but not urgent)
Examples:
- Webhook backlog growth
- KYC vendor latency rising
- Queue depth above normal
- DB connection saturation
3) Notify on informational anomalies (triage later)
Examples:
- Elevated retries
- Small error-rate uptick
- Non-critical batch job delays
Use multi-window burn-rate alerts for SLOs
Instead of paging on a single threshold breach, use burn-rate logic (fast window + slow window) so you catch fast outages and slow burns.
| Alert type | What it catches | Example |
|---|---|---|
| Fast burn | Sudden outage | Deposit success rate collapses over 5 minutes |
| Slow burn | Gradual degradation | Approval rate down 2% all afternoon |
| Segment burn | Localized damage | One PSP in one country failing |
Build “dependency health” dashboards for third parties
For each PSP and game provider, maintain:
- Success rate
- Latency percentiles
- Timeout rate
- Error taxonomy (network, auth, validation, provider internal)
This speeds vendor escalations because you can send evidence, not screenshots.
Step 6: Don’t forget synthetic monitoring (and make it realistic)
Real-user monitoring is essential, but synthetic checks catch breakage earlier if you design them properly.
Good iGaming synthetic checks:
- Lobby to game launch in a sandbox environment
- Deposit intent creation (without moving money)
- KYC vendor health endpoint plus a full verification test in staging
- Webhook receiver health and latency
If you do run transaction-like synthetics, keep them compliant (no real-money movement, no real PII).
Reference stack: tools that commonly work for iGaming observability
There is no single “best” toolchain, but strong patterns exist:
- Instrumentation: OpenTelemetry SDKs + collector
- Metrics: Prometheus-compatible storage, Grafana for dashboards
- Logs: OpenSearch/Elasticsearch or Loki, with strict PII redaction
- Traces: Tempo, Jaeger, or a managed APM tracer
- Alerting: Alertmanager or managed alerting with routing, dedupe, and on-call schedules
For high-volume telemetry, many iGaming teams use columnar stores for time-series style queries. If you’re comparing options, Spinlab’s breakdown of time-series databases for iGaming telemetry can help frame trade-offs.
Incident operations: treat reliability like a 24/7 service business
Reliable iGaming operations are closer to logistics than to casual web apps. If you have ever depended on a 24/7 airport car service, you know the expectation: status updates, predictable ETAs, and fast escalation when reality changes.
Apply the same discipline:
- One “source of truth” incident channel
- Clear ownership per domain (payments, games, KYC, infra)
- Runbooks linked directly from alerts
- Post-incident review that produces a measurable change (new alert, new trace attribute, new guardrail)
A 14-day rollout plan (practical and achievable)
Days 1 to 3: Choose SLOs and build a minimal incident dashboard
Define 3 to 5 SLOs tied to your highest-revenue journeys. Build one dashboard that shows those SLIs segmented by rail/provider/market.
Days 4 to 7: Add tracing to one money journey
Instrument the deposit flow end-to-end with correlation IDs, error reason codes, and async propagation across webhooks and queues.
Days 8 to 11: Implement burn-rate paging and dependency health panels
Page only on SLO symptom alerts. Add separate panels per PSP and per game provider so escalations are evidence-driven.
Days 12 to 14: Add data governance and on-call readiness
Make sure logs and traces have:
- PII redaction rules
- Retention policies by data type
- Access controls and audit logs
Then run a game-day exercise (a controlled incident simulation) and fix what breaks.
Frequently Asked Questions
What are the most important metrics for iGaming observability? Start with player-journey SLIs: deposit success rate and time-to-credit, game launch success rate and time to first spin, withdrawal time-to-paid, and KYC completion rate and latency. Segment them by rail, provider, and market.
Should we prioritize metrics or traces first? Metrics first for fast detection, then traces for fast diagnosis. A good sequence is: define SLOs → instrument SLIs → add tracing to the highest-impact journey (usually deposits or game launch).
How do we avoid noisy alerts in a casino platform? Page only on SLO symptom alerts, use multi-window burn-rate logic, and route cause alerts (like queue depth or webhook lag) to tickets instead of pages.
How do we trace a deposit flow that uses asynchronous webhooks? Propagate a payment_intent_id and trace context across the webhook receiver, queue/event stream, and ledger posting consumer. Link spans across async boundaries and always sample error and slow traces.
How do we handle PII in logs and traces for gambling compliance? Use structured logging with allowlists, tokenize sensitive fields, redact at ingestion, enforce least-privilege access, and apply retention policies aligned to jurisdiction and your DPA obligations.
Build observability into a platform that’s designed to scale
If you’re launching or scaling an online casino, observability gets easier when your core stack is consolidated: payments, wallet, game aggregation, compliance, and analytics all emit consistent events and identifiers.
Spinlab Studio’s modular iGaming platform is built for fast onboarding and operational control, including an integrated real-time analytics layer and an API-first approach that helps teams standardize event contracts across payments, gameplay, and backoffice workflows.
Explore the platform at spinlab.studio and book a walkthrough if you want to map these metrics, traces, and alerts to your exact payment rails, markets, and providers.